
Actualmente más y más empresas de diferentes sectores están optando por la ciencia de datos. Como se pudo apreciar anteriormente, debido a que actualmente se trabaja con una gran cantidad de datos, saber manipular dichos datos usando algún lenguaje de programación se convierte en algo de suma importancia.
Actualmente más y más empresas de diferentes sectores están optando por la ciencia de datos. Como se pudo apreciar anteriormente, debido a que actualmente se trabaja con una gran cantidad de datos, saber manipular dichos datos usando algún lenguaje de programación se convierte en algo de suma importancia.
Como se aprendió anteriormente (ir a Python: Pandas DataFrame manipulación de datos), la libraría pandas es un método bastante amigable cuando se trata de manipular datos ya que te permite visualizarlos de forma ordenada como en una hoja de Excel (en tabla por filas y columnas). Sin embargo, hay otro método igual de importante. El segundo método es la librería numpy. Esta librería ordenará los datos en listas que pueden ser tratados como vectores o matrices dependiendo de su dimensión. En este ejercicio, veremos como manipular datos usando esta librería.
Antes de comenzar, recordemos nuestra clase de matemáticas de la escuela secundaria. ¿Qué es una matriz? Una matriz es una forma de ordenar números por filas y columnas para formar un array rectangular. Un ejemplo de matriz puede ser el siguiente:
Como se puede apreciar, la matriz tiene 2 filas y 4 columnas. En otras palabras, tiene unas dimensiones de 2x4. En caso de que el número de filas y columnas sea el mismo, la matriz se vuelve cuadrada. En programación, si la matriz tiene una sola fila, se conoce comúnmente como vector fila, y si tiene una sola columna, es vector columna.
Se puede obtener un elemento específico de la matriz conociendo su posición. Por ejemplo, el elemento en la posición 2, 4 es el número 8. ¿Cómo entender esto? ¡Pues es muy sencillo! El primer número 2 significa la fila (segunda fila), y el número 4 es la columna (cuarta columna) donde se encuentra el elemento. Dicho esto, cuando trabajes con un array en Python, ¡piensa en las matrices! ¡Empecemos a programar!
Para este ejercicio, trabajaremos con los datos que descargamos de la web (vaya a Python: Descarga de datos de la web" ). Lo primero que debemos hacer es importar el archivo de texto a Python. Para ello utilizaremos la biblioteca pandas.
#Importing library
import pandas as pd
#Importing the .txt file
df = pd.read_csv('vaccinations.txt', header = None, skiprows = (1), sep = ',', quotechar = None, quoting = 3)
print(df)
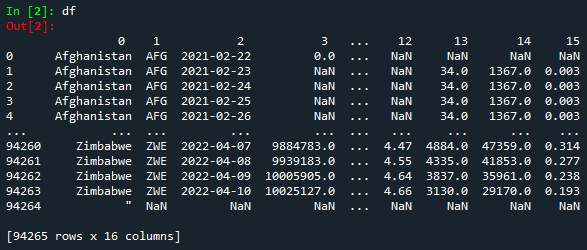
Dado que nuestro objetivo es trabajar con la biblioteca numpy, convertiremos el DataFrame en un array.
#Converting the DataFrame into array
array_data = np.array(df)
print(array_data)
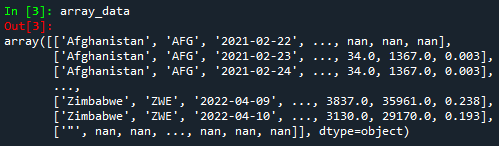
Si prestas atención a la figura anterior, notarás que cada línea está dentro de los corchetes ('[ ]') y cada elemento está separado por la coma delimitadora (',')). Esto significa que todo lo que está dentro de los corchetes representa una fila y cada elemento dentro representa una columna.
Python comienza a contar el número de filas y columnas desde 0. Esto significa, por ejemplo, que el elemento de esa matriz con la posición 2, 1 será 'AFG', o el elemento con la posición 0, 2 será '2021- 02-22'.
Ahora, comencemos a manipular datos. De manera similar a DataFrame, podemos obtener las primeras 5 filas (con todas las columnas) y las primeras 5 columnas (con todas las filas).
#Selecting the first 5 rows (from 0 to 4)
first_rows = array_data[:5,:]
print(first_rows)
#Selecting the first 4 columns (from 0 to 3)
first_columns = array_data[:,:4]
print(first_columns)
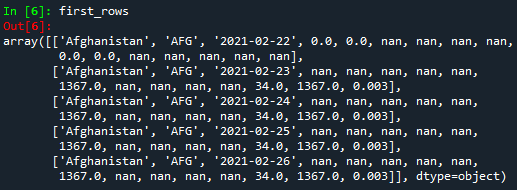
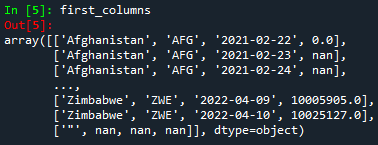
Pero... ¿cómo entender el código anterior? ¡Pues es muy sencillo! Por ejemplo, en el primer caso, [:5,:] la coma ',' delimita filas y columnas. Para seleccionar todas las filas o columnas, se utilizan los dos puntos ':'. En el caso de las filas, :5 significa que se tendrán en cuenta las primeras 5 filas. Dado que Python comienza a contar desde 0, las primeras filas serán 0, 1, 2, 3 y 4. ¡Tenga en cuenta que la fila 5 no está incluida!
Ahora, copiemos el array en otro array para conservar el original.
#Copying the array to another array
array_copy = array_data.copy()
print(array_copy)
Veamos ahora cómo eliminar filas y columnas específicas. Para este propósito, se necesita la función numpy.delete().
#Removing one or multiple rows
delete_rows = np.delete(array_data, [100, 525, 9461], axis=0)
print(delete_rows)
#Removing one or multiple columns
delete_columns = np.delete(array_data, [2,7,11], axis=1)
print(delete_columns)
Tenga en cuenta que en el código anterior, axis=0 significa eliminar filas, mientras que axis=1 significa columnas. Después de ejecutar el código, obtendremos lo siguiente:
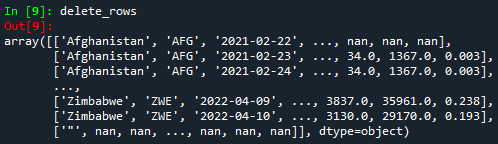
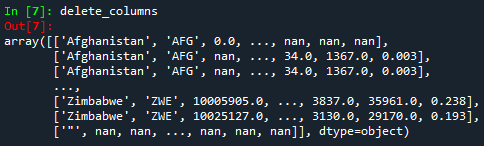
Dado que no es visible que acabamos de eliminar filas y columnas específicas, ¡vamos a demostrarlo! Para probarlo, podemos pedirle a Python que nos dé las dimensiones de los nuevos arrays ('delete_rows' y 'delete_columns') y el array 'array data'. Para ello utilizaremos la función numpy.size().
#Comparing arrays
#Getting the number of columns
rows1 = np. size(array_data, 1)
print(rows1)
rows2 = np. size(delete_columns, 1)
print(rows2)
#Getting the number of rows
columns1 = np. size(array_data, 0)
print(columns1)
columns2 = np. size(delete_rows, 0)
print(columns2)
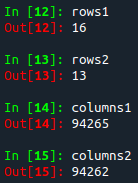
En la imagen de arriba, las variables 'rows1' y 'columns1' son las dimensiones del array 'array data' original, mientras que las variables 'rows1' y 'columns1' son las dimensiones del mismo array después de eliminar las filas [100, 525 , 9461] y columnas [2,7,11]. Se puede observar que la cantidad de filas y columnas ha disminuido como debería, ya que eliminamos 3 filas y 3 columnas.
Ahora, obtengamos valores específicos según una determinada condición. Por ejemplo, obtendremos los datos solo para un país específico: Perú. Podemos usar la función input para que el usuario ingrese su país deseado.
#Getting data per country (Selecting all rows where the first column is equal to 'country')
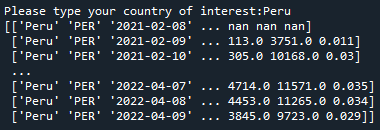
country = input('Please type your country of interest:')
array_data_country = array_data[array_data[:,0] == country]
print(array_data_country)
Al igual que en el tutorial anterior sobre la libreríapandas, exportaremos el array ingresado por el usuario a Excel. La forma más fácil de lograr esto es convirtiendo el array en DataFrame (utilizando la función pandas.DataFrame()), y luego exportándolo a Excel (usando la función df.to_excel()) como se muestra en el tutorial anterior.
Sin embargo, hay otra forma de exportar una matriz numpy, que se mostrará en este tutorial. Lo primero que debemos hacer es importar la biblioteca xlswriter. Luego, deberíamos 'abrir' un libro de trabajo y una hoja de Excel usando la codificación de Python. Para esto, existen funciones especiales en Python como se muestra:
#Exporting array to Excel
import xlsxwriter
#Creating the Excel file
#Creating the workbook
workbook = xlsxwriter.Workbook('Vaccinations by country.xlsx')
#Creating the worksheet
worksheet = workbook.add_worksheet()
Después de crear el archivo de Excel, antes de comenzar a exportar el array, primero debemos establecer un encabezado para él. Para esto, creamos una lista en Python con los diferentes nombres de columna para el encabezado, y luego debemos iterar a través de cada elemento de esa lista y escribirlo en la primera fila en Excel.
#Getting data per country (Selecting all rows where the first column is equal to 'country')
country = input('Please type your country of interest:')
array_data_country = array_data[array_data[:,0] == country]
print(array_data_country)
¡No olvides que Python comienza a contar desde 0! Es por eso que se establece la fila igual a cero. La función enumerate(header) le dice a Python que itere a través de cada elemento de la list header. Luego, la función worksheet.write() escribirá los datos iterados en la primera fila de Excel. Ahora es el momento de hacer lo mismo, ¡pero para los datos en sí! Aplicaremos la misma lógica que para el encabezado.
#Iterating over the array data to export to Excel
column = 0
for row, data in enumerate(array_data_country):
try:
worksheet.write_row(row+1, column, data)
except:
pass
El último paso a realizar es cerrar el archivo de Excel usando la función workbook.close().
workbook.close()
Después de ejecutar este código, encontrarás el archivo de Excel creado en el mismo directorio que su archivo de Python.

El código completo se verá así:
#Importing the library
import numpy as np
import pandas as pd
import xlsxwriter
#Importing the .txt file
df = pd.read_csv('vaccinations.txt', header = None, skiprows = (1), sep = ',', quotechar = None, quoting = 3)
print(df)
#Converting the DataFrame into array
array_data = np.array(df)
print(array_data)
#Selecting the first 5 rows (from 0 to 4)
first_rows = array_data[:5,:]
print(first_rows)
#Selecting the first 4 columns (from 0 to 3)
first_columns = array_data[:,:4]
print(first_columns)
#Copying the array to another array
array_copy = array_data.copy()
print(array_copy)
#Removing one or multiple columns
delete_columns = np.delete(array_data, [2,7,11], axis=1)
print(delete_columns)
#Removing one or multiple rows
delete_rows = np.delete(array_data, [100, 525, 9461], axis=0)
print(delete_rows)
#Comparing arrays
#Getting the number of columns
rows1 = np. size(array_data, 1)
print(rows1)
rows2 = np. size(delete_columns, 1)
print(rows2)
#Getting the number of rows
columns1 = np. size(array_data, 0)
print(columns1)
columns2 = np. size(delete_rows, 0)
print(columns2)
#Getting data per country (Selecting all rows where the first column is equal to 'country')
country = input('Please type your country of interest:')
array_data_country = array_data[array_data[:,0] == country]
print(array_data_country)
#Exporting array to Excel
#Creating the Excel file
#Creating the workbook
workbook = xlsxwriter.Workbook('Vaccinations by country.xlsx')
#Creating the worksheet
worksheet = workbook.add_worksheet()
#Creating a list for the header in Excel
header = ['Country','Country iso code','Date','Total vaccinations','People vaccinated','People fully vaccinated','Total boosters','Daily vaccinations raw','Daily vaccinations','Total vaccinations per hundred','People vaccinated per hundred','People fully vaccinated per hundred','Total boosters per hundred','Daily vaccinations per million','Daily people vaccinated','Daily people vaccinated per hundred']
#Iterating over the header to create the first row in Excel
row_header = 0
for column_header, data_header in enumerate(header):
worksheet.write(row_header, column_header, data_header)
#Iterating over the array data to export to Excel
column = 0
for row, data in enumerate(array_data_country):
try:
worksheet.write_row(row+1, column, data)
except:
pass
workbook.close()
¡Felicitaciones! ¡Ahora te convertiste en un experto en la manipulación de datos con Pandas DataFrame y Numpy array! Para descargar el código completo y el archivo de texto con los datos usados en este tutorial, haz click aquí.
Vistas: 1 Github
Artículos Relacionados




Notificaciones
Recibe los nuevos artículos en tu correo electrónico
Otros Artículos

12 curiosidades de vivir en Alemania
stats con chris

El método de los mínimos cuadrados con Despacito
stats con chris

Diferencias entre la Bolsa de Valores de Japón y de EEUU
stats con chris

